AI-Enhanced Discovery for 45 TB of Weather & Climate Data
A metadata catalog that combines Python-powered crawling, LLM enrichment, and semantic search to make decades of NOAA observation and model data discoverable and accessible.

 View Online
View Online
A Wealth of Data, Ready to Be Unlocked
GSL's /public disk holds decades of operational weather observations,
model output, satellite imagery, radar data, and retrospective case studies — a rich archive built and maintained by
scientists across the lab. The goal: make that deep institutional knowledge accessible to everyone.
Experienced staff carry invaluable knowledge of what’s on the depot. This tool helps capture and share that expertise so new team members can get up to speed faster.
With 120+ datasets across nested directories, even experienced users can miss relevant data. A searchable catalog surfaces connections that browsing alone can’t.
Dozens of formats (netCDF, GRIB, BUFR, HDF5), 6 root directories, datasets spanning 1996–present. Keeping up requires automation.
Built for Scientists
A single-page React app with no build step — designed for fast, intuitive exploration of the depot’s full catalog.
Three modes: keyword matching, semantic similarity via embeddings, and a 40/60 hybrid blend. Autocomplete with instant suggestions.
Natural language Q&A powered by RAG. Ask “What satellite data covers the Gulf of Mexico?” and get grounded answers.
Natural Earth coastlines with drag-to-select bounding box filtering. See spatial coverage at a glance across all datasets.
Temporal coverage bars for every dataset. Expandable detail showing date ranges, update frequency, and data freshness status.
9 organized categories — Observation Type, Model/System, Domain, Phenomenon, and more. Click to filter, combine to narrow.
Expandable cards with relevance scores, AI descriptions, related datasets, format breakdowns, and JSON export capability.
Explore the Data Depot
HRRR
aircraft observations
satellite data over Gulf of Mexico
Search across 120+ datasets by keyword, spatial extent, time range, or natural language.
To run the explorer locally:
git clone https://github.com/NOAA-GSL/data-depot.git cd data-depot docker compose up -d --build # starts on :8080
Then open localhost:8080 — or view the poster from there at localhost:8080/poster/ for a live interactive demo.
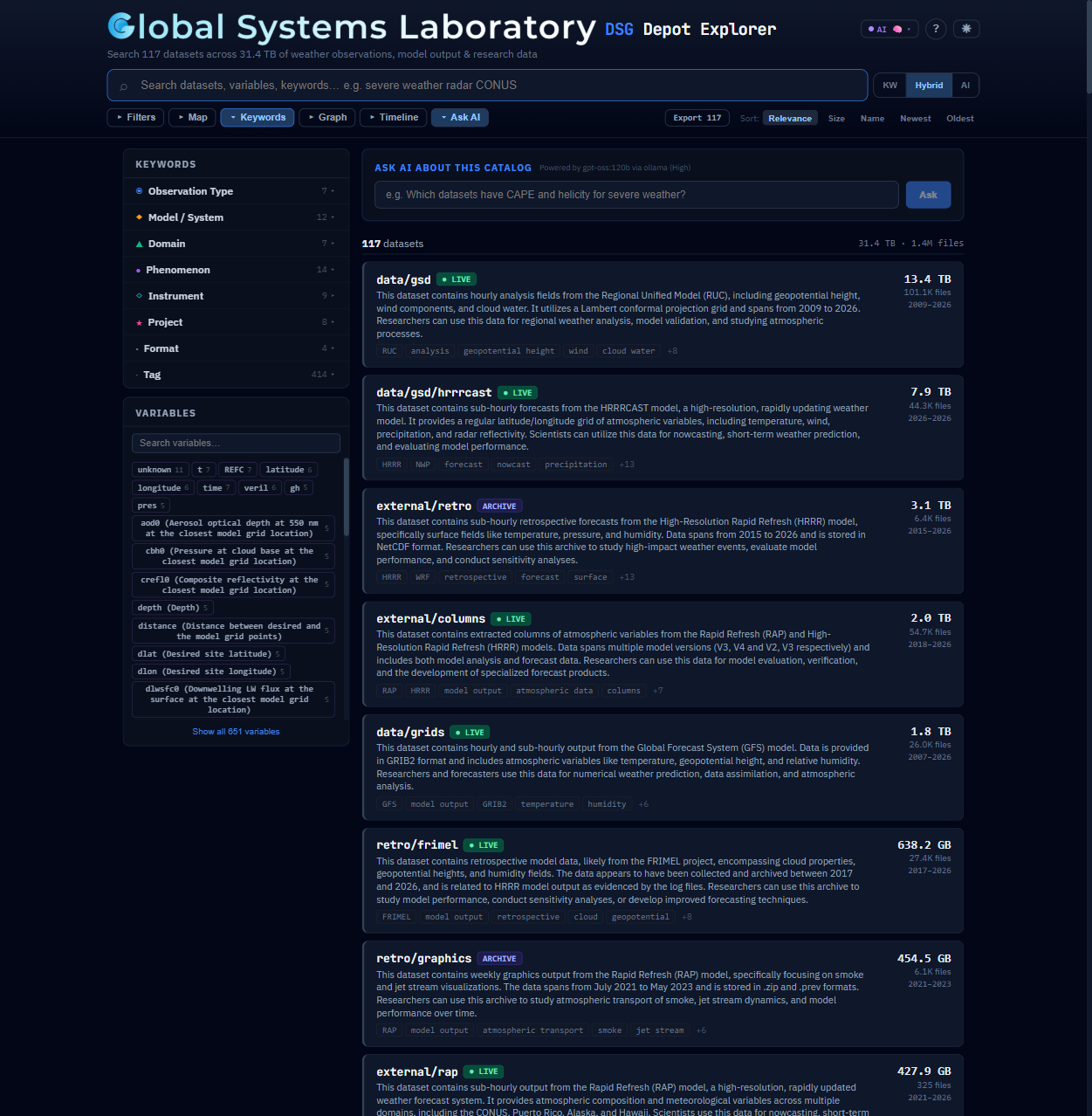
From Raw Disk to Searchable Catalog
A Python-powered pipeline automatically walks the depot, extracts structured metadata, enriches it with AI, and serves it through a standards-compliant API.
What the Crawler Captures
- Directory trees with file counts, sizes, and extension breakdowns
- Date ranges (earliest/latest file timestamps)
- Update frequency estimation from timestamp intervals
- NetCDF/GRIB/BUFR header sampling for variable names
- Documentation files (READMEs, CDL schemas)
- Domain keyword tagging from 177+ term vocabulary
Automated Scheduling
- Runs as a daily Kubernetes CronJob
- Incremental mode — only re-crawls changed directories
- Freshness detection:
active,stale, orarchive - Fast structure-only mode with
--no-sampling - Enricher CronJob runs later in the day
- Search index files tracked in Git for versioning
From Raw Metadata to Rich Context
The crawler captures structure; LLMs add understanding. A local Ollama instance analyzes each dataset’s metadata and generates human-quality descriptions, categorization, spatial inference, and scientific use cases.
Crawler Output
data/acars.nc .cdf .bin+ AI Enrichment
observation[-90, -180, 90, 180]Cosine similarity on embeddings, blended with keyword matching
Natural language Q&A with retrieval-augmented generation
Bounding box and human-readable coverage from context
Automatic classification into 9 dataset categories
STAC-Compliant API with AI Extensions
The catalog exposes a full STAC v1.1.0 API alongside custom AI endpoints — making the depot discoverable by standard geospatial tools while offering intelligent search capabilities beyond what STAC provides.
STAC Core Endpoints
Standards-compliant for interoperability with QGIS, pystac-client, and STAC Browser.
GET /stac/Landing pageGET /stac/collectionsAll datasets as CollectionsGET /stac/collections/{id}/itemsSubdirectory ItemsGET|POST /stac/searchCross-collection search
AI-Extended Endpoints
Custom endpoints that go beyond STAC for intelligent discovery.
GET /api/search/semanticHybrid keyword + embedding searchGET /api/ask?q=...Natural language Q&APOST /api/chatMulti-turn conversationGET /api/ai/statusOllama model availability
Dataset → STAC Collection · Subdirectory → STAC Item · Custom dsg: extension for freshness status, AI category, contacts, and depot paths.
Enabling Automated Workflows
With a standards-compliant API, the Data Depot becomes more than a browsable archive — it’s a programmable data source. The Zyra Editor can treat it as a first-class node in visual data processing pipelines, connecting search and acquisition directly to downstream analysis.
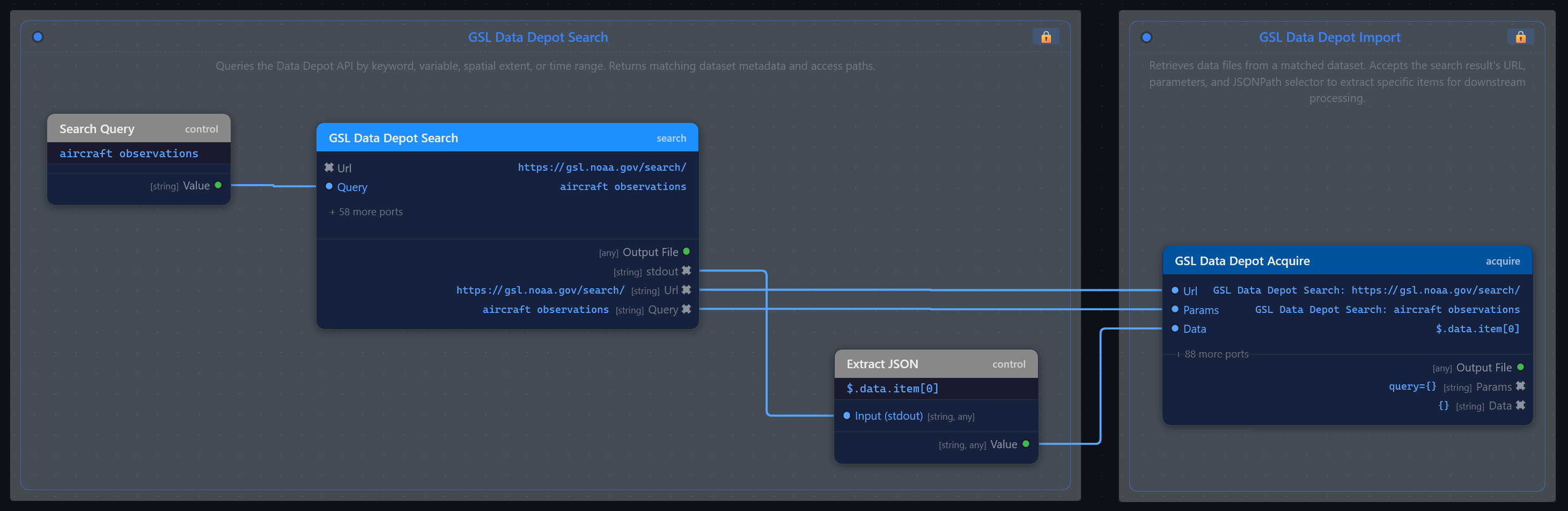
Queries the Data Depot API by keyword, variable, spatial extent, or time range. Returns matching dataset metadata and access paths for downstream nodes.
Retrieves data files from a matched dataset. Accepts the search result’s URL, parameters, and JSONPath selector to extract specific items for downstream processing.
Up next: The Zyra Editor presentation explores how visual pipeline building and agent-driven orchestration are transforming scientific data workflows.
 Zyra Editor Poster
Zyra Editor Poster
Tech Stack
Frontend
- React 18 + Babel Standalone
- Single HTML file, no build step
- Natural Earth map rendering
- Dark/Light theme support
- Responsive, mobile-friendly
Backend
FastAPI+Uvicorn- Python 3.12
- STAC v1.1 router (
stac.py) - 21 REST endpoints
- In-memory index (~121 datasets)
Infrastructure
- Docker + Docker Compose
- Kubernetes (deployment + CronJobs)
- Ollama for local LLM inference
nomic-embed-textembeddings- 82 automated STAC tests